10月23日下午,世界音乐人工智能大会论坛三:音乐人工智能博士论坛,在北京民族文化宫举办。

世界音乐人工智能大会(Summit on Music Intelligence)10月22日-24日在北京开幕。大会由中央音乐学院(CCoM)与中国人工智能学会(CAAI)联合主办,汇聚全球音乐人工智能顶尖专家、学者、相关领域具有影响力的领军人物以及音乐产业相关企业代表等,集思广益,精骛八极,共同探究未来音乐世界,推动音乐人工智能“产、学、研、用”的发展,服务北京、服务国家战略,与世界携手未来。开幕前夕,国际物理学家、诺贝尔物理学奖获得者李政道先生为大会题词祝贺:科学与艺术的交融,艺术与科学的盛会,祝世界音乐人工智能大会圆满成功!

音乐人工智能博士论坛由世界音乐人工智能大会执行主席、中央音乐学院音乐人工智能与音乐信息科技系主任李小兵教授主持,发言嘉宾由六位正在音乐人工智能系就读的博士生构成。

据李小兵教授介绍,这六位同学,有的已经事业有成,仍然选择带着丰富的经验和资源回到学校继续学习,有的还没走出校门,就已经被上市公司高薪签走。他们是中央音乐学院音乐人工智能与音乐信息科技系诸多优秀博士生的代表和缩影,让我们看到这个行业、这份事业蒸蒸日上的未来。他鼓励青年学子发奋努力,为世界创造惊喜。

报告题目:基于发声物理模型的歌声反演方法研究
论坛嘉宾:
江超
中央音乐学院音乐人工智能博士
江超,毕业于南京大学,获电子学学士学位,声学硕士学位。全国电声学标准化技术委员会委员,中国声学学会音频工程分会委员,中国电子元件行业协会技术委员。2019年成为中央音乐学院音乐人工智能与音乐信息科技专业博士研究生,师从俞峰教授和吴玺宏教授。
报告摘要:
本报告介绍了一种新的歌声反演方法。该方法首先利用声带振动的双质模型,及声道的管道共振模型构建了一个完整的发音物理模型。该模型通过使用声带和声道的物理参数,可以合成语音和歌声信号。同时,利用该物理模型提出了一种新的自监督学习方法以解决反演问题。该方法采用综合分析的方式,通过迭代采样和训练学习推理网络,得到的结果具有明确的物理意义。通过该方法,我们可以通过歌声信号,反演歌者在演唱时的声带和声道的物理参数,从而定量分析各种不同声部和风格的歌者演唱时的技术特点。

报告题目:基于深度学习技术的多轨道与多乐器自动作曲
论坛嘉宾:
刘家丰
中央音乐学院音乐人工智能博士
刘家丰,资深人工智能算法专家,中央音乐学院首届音乐人工智能与音乐科技博士生。曾就职于美国纽约爱迪生联合电气,担任数据科学家一职。自幼学习钢琴,师从四川音乐学院钢琴系教授,本科与研究生期间曾担任校交响乐团首席钢琴。现致力于使用人工智能技术,探索多轨道自动作曲、多轨道自动转谱、音源分离等相关科研方向。
报告摘要:
近年来,深度学习技术在自动作曲上的研究已经成为一个快速增长的领域。之前的工作主要集中在单旋律与复调生成、固定多轨道生成等任务,对于可变多轨道多乐器的研究仍然较少。本次报告内容主要集中在如何针对多轨道多乐器的音乐进行数据建模,同时提出世界上首个最大的交响乐数据集。其中包括在针对交响乐的表示学习上面的创新,使用线性自注意力解决更长的序列捕捉能力,在采样时进行可控生成等诸多创新。

报告题目:解耦音高和节奏的自动旋律和声配置
论坛嘉宾:
吴尚达
中央音乐学院音乐人工智能博士
吴尚达,湖南郴州人。现就读于中央音乐学院,2021级音乐人工智能博士生,师从孙茂松教授和俞峰教授。主要研究兴趣为深度学习算法在符号音乐领域中的应用。2015年至2019年本科就读于星海音乐学院,主修钢琴表演。2019年考入中山大学计算机学院攻读硕士学位,主修软件工程。
报告摘要:
和弦对歌曲以及器乐创作往往起着关键的指导作用。然而,由于其多模态的性质,为用户给定的旋律生成适当的和声进行至今仍是一项充满挑战的任务。当前,仅有少数研究关注基于神经网络的自动旋律和声配置,它们不仅难以生成符合给定旋律又兼具变化的节奏型,而且可以生成的和弦种类比较有限。为了在这项任务中实现更好的灵活性,我们提出了一个将音高和节奏解耦的基于神经网络的自动旋律和声配置模型。这个模型主要由两个部分组成:节奏解码器用于提供粗粒度的和弦起音信息,而和弦解码器则根据给定的旋律和先前由节奏解码器生成的对应序列,为和弦生成特定的音高。初步的生成结果表明,模型配置的和弦不仅有着分布良好的节奏,而且和声进行也比较合理。在未来,我们计划将这个模型移植到浏览器上,为音乐爱好者和艺术家提供一种兼具便捷和交互性的音乐创作方式。
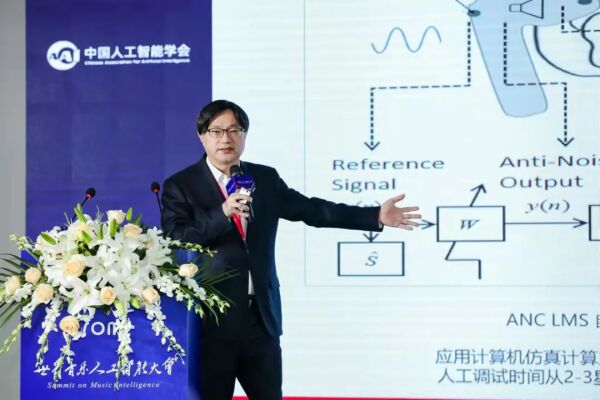
报告题目:万物有声——人工智能技术在声学领域的应用
论坛嘉宾:
谢冠宏
中央音乐学院音乐人工智能博士
谢冠宏,现就读于音乐人工智能与音乐信息技术专业。为1MORE 万魔声学创始人及董事长,创立中国原创耳机品牌,8年全球销量超 8,500 万支。曾为美格联合创始人,任职于富士康集团十年,主导过 Apple iPod、Amazon Kindle 等知名消费电子的设计生产。作为发明人,全球授权专利超过 1300 项。
报告摘要:
随着近年来智能音频设备的高速发展,人工智能技术在声学方面的应用正在成为趋势。通过将AI技术应用于ENC、ANC,可有效解决耳机降噪问题和语音质量问题,提高工作效率,减少产品不良率等。
我们采用LMS结合DNN神经网络的算法实现滤波器参数最优化。以采集的传递函数样本作为输入进行模型训练,通过使待优化传递函数与目标传递函数均方误差最小化,输出各滤波器最优化参数,测试表明ANC降噪深度和降噪宽度符合滤波器设计要求。
我们采用基于深度学习DNN的语音增强算法可解决低信噪比时噪声消除不干净问题,具体采用对声音的相位和幅度信息进行非线性建模,保留清晰音色,噪声残余稳定舒适,利用深度学习后处理技术降低残留噪声影响,进一步提升增强语音质量。
我们采用不同环境自动匹配不同ANC模式降噪,实现环境的自适应降噪。具体采用基于环境噪声能量分布和语音活动分析,对不同环境自动匹配相应ANC模式,实现不同环境下降噪深度最优以及舒适性提升。
除此之外,针对音乐内容智能化部分,云端运算引擎通过用户的使用习惯在不同的时间和场景推送相应的音乐内容或有声书籍,或将用户需要阅读的网页内容转化为有声读物。目前已落地并经过临床试验的产品是万魔睡眠豆耳机,此产品与深大总医院合作并经实际用户睡眠监测,试验数据证明可有效缩短用户入眠时间,加长深睡时间,为有效的促眠产品。

报告题目:小提琴演奏的具身学习
论坛嘉宾:
袁野
中央音乐学院音乐人工智能博士
袁野,2008年本科毕业于清华大学计算机科学与技术系,2017年硕士研究生毕业于中国音乐学院音乐教育系音乐教育学专业,2019年起在中央音乐学院攻读音乐人工智能专业博士。有钢琴演奏背景,作曲的多部合唱与剧场音乐作品参加公演,并多年担任合唱团指挥和艺术总监。
报告摘要:
传统离身认知理论基于表征计算主义,它虽然在一些领域的实践中取得成功,却始终受到来自生物进化论、教育学和知觉现象学等多学科的质疑。在小提琴表演这一音乐活动中,凝聚着人类身体以及文化的全部经验,唯有使用具身认知理论才可能理解并学习其中蕴含的知识。现有的小提琴演奏模型只包含乐符域和声音域,缺少了动作域,而这是小提琴具身认知的核心环节。
本研究实现一个人工神经网络模型及相应的学习方法,学会由小提琴声音推断其演奏动作,从而获得小提琴的动作域表示。学习过程以一个小提琴发声的物理模型为身体,不借助人工标注,而且声音未经“音符”等中间符号表示抽象,最终动作可以在时间上连续控制。该模型与小提琴发声的物理模型一起,构成对小提琴演奏的具身认知。
通过在动作域上进行操作,我们可以控制物理模型,产生真实多变的小提琴声音。一套动作语言还可以辅助演奏教学、辅助音乐形态分析。进一步的,若将动作域表示与乐符域关联,模型可以演奏乐谱,并表达出不同的动作风格特征,获得更多交互式的表演可能。

报告题目:符号音乐生成及相似度技术
论坛嘉宾:
张昕然
中央音乐学院音乐人工智能博士
张昕然,中央音乐学院博士研究生。首个博士毕业于北京邮电大学信息与通信工程学院。2019年以专业第一排名考入中央音乐学院。先后师从俞峰教授、孙茂松教授、王文博教授、孙松林教授等。共发表SCI、EI论文二十余篇,发明专利6项。
报告摘要:
生成任务和相似度任务是语言模型的重要应用,也是基于语言模型的音乐人工智能技术的研究重点。本报告主要围绕符号音乐的生成任务和相似度任务开展研究。针对生成任务的退化问题,提出IQR-IP随机采样算法,通过逆概率加权方法抑制高频词的概率,从而降低重复、缓解退化问题,提高生成任务的多样性。针对生成任务的可控多样性问题,提出NS-RH随机采样算法,通过高频词随机化方法实现可控多样性的生成任务。在文本数据和符号音乐数据上验证了所提出采样算法的性能,相比传统采样算法,所提出的算法能显著提升生成任务的多样性和新颖性。提出“灵犀”歌词辅助写作系统,并搭建了基于web的系统,实现端到端的歌词生成。针对符号音乐相似度问题,提出基于嵌入校准技术的音乐相似度框架,以无监督方式构建次优评测数据集,给出最优嵌入校准方案,可在不依赖于人工标注的条件下提升符号音乐相似度技术的性能。基于符号音乐生成技术,提出四部和声补全算法,可以在给定声部旋律条件下生成巴赫风格四部和声符号音乐。

世界音乐人工智能大会与会者合影(10月23日)

世界音乐人工智能大圆桌讨论专家与参会者合影
(10月24日)

大会联系方式:
邮箱:SOMI@ccom.edu.cn
电话:010-6641 5568
大会官网:
中文 https://www.somi-ccom.com/
英文 https://www.somi-ccom.com/en/
项目支持:教育部“双一流”建设高校和建设学科;北京市高校高精尖学科;北京宣传文化引导基金






